
A Scenario:
Ever wonder why we VMware Engineers always try to explain to you why, “you don’t need that many vCPUS”?
But then you insist that you do need them because, “that’s what the vendor told you and stuff. . . or . . . whatever.”
And then we’re all, “Right, but we have this vROPs report that you have direct access to but never use says you don’t need them.”
And then you’re like all nonchalant and stuff, “Yeah but, like, the vendor says they won’t support it if it doesn’t have 128 vCPUS and 40TB of RAM and stuff.”
And then we say, “Right, but that’s going to cost the company, like, $25,000 and stuff.”
And then you go, “Yeah but we’re not paying for it and stuff, so it’s cool, I’ll just ask Management to pay for it, bruh.”
END SCENE
I have been a VMware Trainer/Engineer since about 2008. I have had that meeting dozens of times, and it can be endlessly frustrating (and costly), so we’re talking about right-sizing your VMs in this post, focusing mostly on Co-stop, but there is a larger message (and rant) here.
The larger lesson here is that you can either pay now in the form of time (load testing), or you can pay later in the form of hardware. What’s less painful for you? I guess that’s your call. But I would say that right-sizing your VMs is usually the best bet. Without it, you are paying for hardware you ultimately should not need.
Right-sizing means that the VM has the “goldilocks” nirvana of having resource allocation that is “just right”: It’s not too small that the application falls on it’s face, but not too big that it suffers from performance issues like the one we are talking about here: Co-stop.
Over the years, we VMware types have had to deal with vendors or application-owners who don’t want to take the time to right-size the resources needed to run their application. There are many reasons excuses as to why they do this:
- They don’t know how virtualization or how relaxed co-scheduling works.
- They assign a “maximum” amount of vCPU count and RAM because they believe in the myth that “more is better”.
- Vendors erroneously believe that if they go with this “more is better” approach, their Tier 1 Support can tick the box, “The VM Has Enough Resources”; in other words if they threaten that, “WE ONLY SUPPORT THIS WITH 32 vCPUS and 512GB RAM!” they (think) their T1 support won’t have to troubleshoot resource allocation issues and can move on to other things.
- They simply don’t take the time to do Perf/Load Testing of their application (or don’t know how), so they do the lazy thing of just going with the “more is better” approach.
This is a daily struggle for us VMware Admins: We know you don’t need the resources you’re asking for, but you demand them anyway. At great cost to the company.
READ THIS PART, FFS
And while I am at it, in the defense of VMware, if you think this is unique to VMware, guess again. SMP and methods for scheduling CPU time are a thing no matter what the platform. It’s just that with the cloud, this is obfuscated away by simply charging you for the usage and management under the hood, but again, you may be over-paying there too.
In fact, AWS actually has right-sizing recommendations that people use all the time to save money, as does vROPS for vSphere, as quoted above, so why would you treat right-sizing any different no matter what the platform?
Pssst . . . That was a rhetorical question.
Co-stop Defined
Here is a definition of Co-stop according to the ESXTOP Official Guide from VMware:
The percentage of time that the VM is ready to run but is waiting for the availability of other vCPUs. The co-deschedule state applies only for SMP VMs. The CPU scheduler might put a vCPU in this state, when the VM workload does not use vCPUs in a balanced fashion. For example, if you have a VM with 2 vCPUs running a non SMP aware application, utilizing 1 vCPU at 100% and 1 vCPU at 0%. In that case, the CPU scheduler penalties the VM to reduce resource shortage for other VMs. This is represented as %CSTP.
What VMware means here, simply, is that a high Co-stop percentage means that the VM in question has too many vCPUs assigned to it and VMware will recommend decreasing the number of vCPUs assigned. This post is about the how and the why of it all.
What You Need to Know to Pick Up What I’m Putting Down Here
First, the assumption I am making here is that we are overcommitting CPU. If there is a 1:1 match between Physical CPU Cores (pCPU) and Virtual CPUs (vCPUs) assigned to the VM(s), then none of this should apply, however, that does not mean Co-stop won’t occur.
Also, a very large implication here has to do with CPU %Overcommit, which is usually converted into a ratio, like #vCPUs:1pCPU. VMware, to my knowledge, has a “soft recommendation” of 3:1 (3 vCPUs to every 1 pCPU core), which is the ratio that most environments will experience no noticeable performance issues.
A ratio of 4:1 qualifies as, . . . ** looks at notes ** . . . “pushing it”.
However, this is highly dependent on the workload and on the nature of the application. I have seen ratios as high as 6:1 with no issues, and ratios as low as 1.65:1 where things have slowed to a crawl. A recurring theme in this post, everyone, is that if you don’t know how to right-size your VMs, contact your friendly neighborhood VMware Engineer.
And finally, there is a difference between “Capacity” versus “Resource Allocation”. They are not the same thing. For example, compare these setups:
- 10 VMs at 8 vCPUs each = 80 vCPUs.
- 20 VMs at 4 vCPUs each = 80 vCPUs.
These setups use the same capacity (this is oversimplifying, but explaining that goes far beyond this post), but have different resource allocations. Each of these can have profoundly different performance implications once we start to scale up.
Why the “More is Better” Approach is Ill-Advised.
Let’s start at the beginning, and I will let you in on some secrets that define the daily lives of us VMware Types:
- This may seem obvious, but modern physical processors have a Virtualization flag that is turned on to support Symmetric Multiprocessing (SMP). I say this because I would imagine that, to this day, people believe that “we need to give VMs the same proc count as in the physical world”. Not necessarily.
- Server-grade processors (Xeon, etc.) are built with high-end server-side processing in mind. It’s not the same experience as with Desktop-grade procs. Not by a long shot. I find that many people don’t realize this, or don’t understand what that means.
- Another major factor here is the type of workload, the heterogeneity of those workloads, and what their load is at any given time on the same host.
All of this adds up to a situation where the CPU co-scheduler is optimized to leverage fewer physical resources in a better way.
Measuring Co-stop and What is Acceptable
There are three major ways you can measure Co-stop (but there may be others):
Here’s a report from vROPS comparing three different clusters. Let me know when you see it . . . (Hint: compare the top cluster with the bottom 2 clusters):
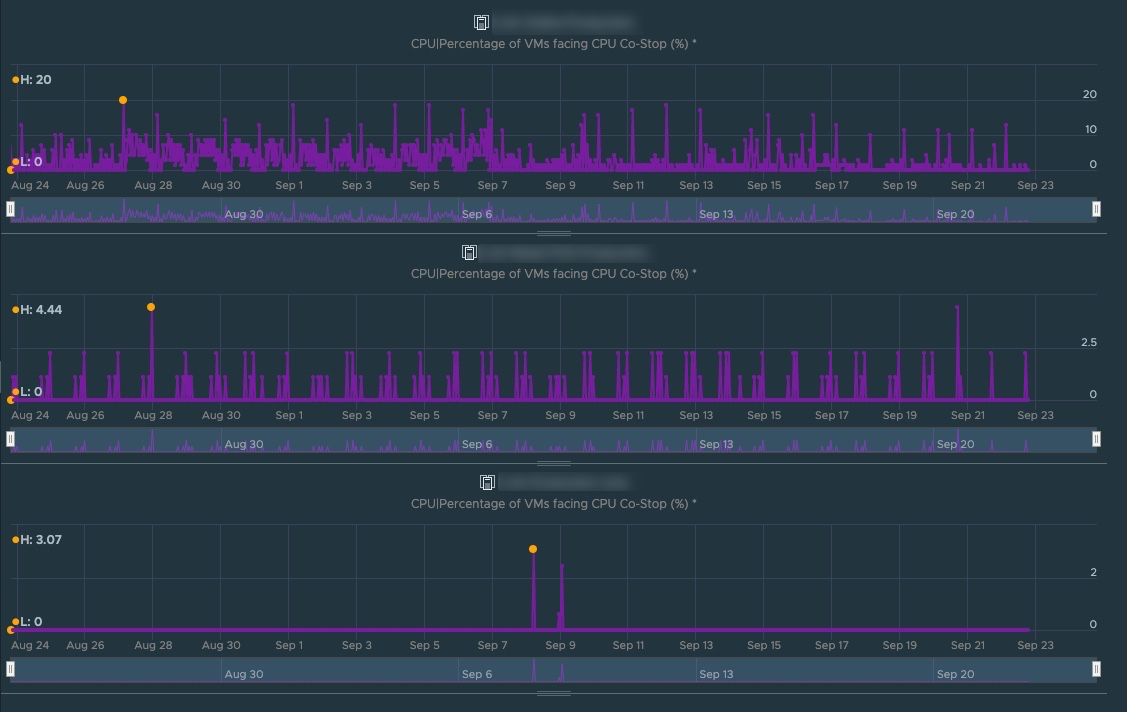
Looking at this chart, be aware the an acceptable Co-stop number is < 3% average. The top Cluster has an average of about 8-10%, but peaks to as high as 20%. Furthermore, Co-stop can also be measured in ms. What this chart isn’t showing you is that some of the VMs in the top cluster were measuring a Co-stop time ranging from 5-56 seconds. That’s seconds, with an s.
So some analysis is due for the top cluster, and vROPS can make some recommendations on a per-VM basis. You can also read VMware’s Performance Guide for tips.
In Closing: Playing Devils’ Advocate
You might be reading this and saying, “Well, Bryan, can’t we just add more hosts to the cluster to bring the ratio down as a whole to reduce the risk that Co-stop will happen?”
The answer is yes, but you would cost the company the average cost of a host, which nowadays is about . . . ** looks at notes ** . . . $25,000 per host.
Which ultimately brings me to the sad fact that a lot of these decisions are, of course, political.
And to be fair, workloads and circumstances change over time. The application changes; the time it is utilized changes. It’s certainly possible that despite all of your due diligence, “right-sizing” is totally different over time. To solve this, continue to report and compare. Due diligence isn’t a one-time thing.
If there are any doubts, you can always read the VMware Performances Best Practices Guide.
Questions? Hit me up on twitter @RussianLitGuy or email me at bryansullins@thinkingoutcloud.org. I would love to hear from you.

One thought