
When I was a wee VMware Engineer (let’s say it was the year . . . I don’t know . . . 2011), I first learned about the clustering features built into vSphere (specifically, HA and DRS). I developed a certain psychology and approach about those clustering technologies that was validated by more seasoned VMware Engineers, some of whom actually worked at VMware. That psychology and approach was as follows:
- Plan for capacity at N+1, both to avoid contention and for singular ESXi Host Failure.
- HA is a peer-to-peer clustering technology that, once configured, recovers VMs whether vCenter is available or not.
- If vCenter is unavailable, DRS will cease to function (VMs stay put until vCenter is back online), but at least the VMs will not go down, and if you have followed the logic and advice of #1 as above, DRS functioning while vCenter is offline is not mission critical. In other words, DRS is way down on your list of priorities if vCenter is unavailable.
But before I disclose my crisis of confidence about vSphere Cluster Service (vCLS), let’s define it.
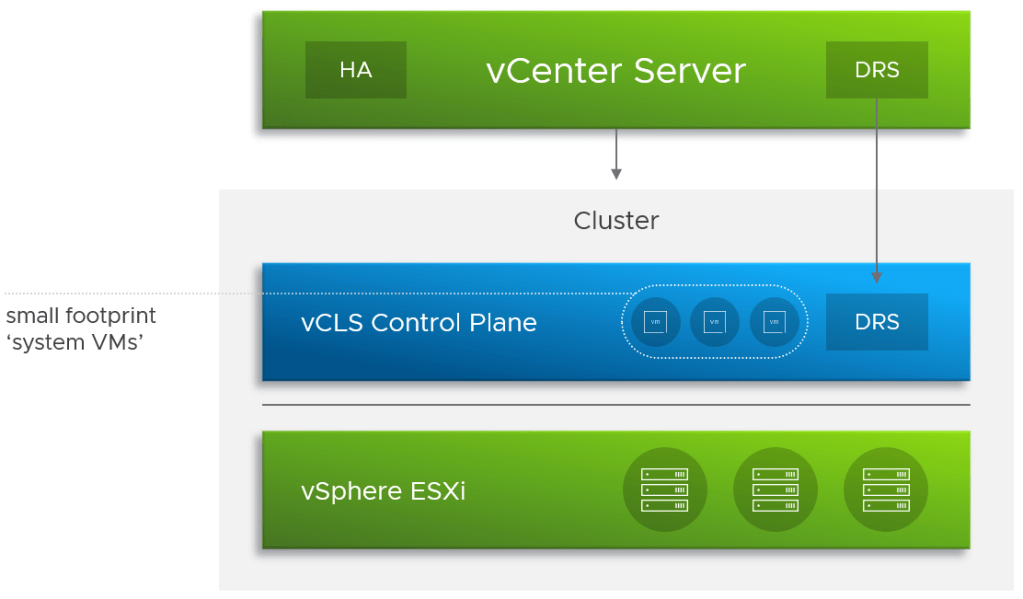
What is vSphere Cluster Service (vCLS)?
Taken straight from VMware’s official documentation about vCLS:
vSphere Cluster Services (vCLS) is enabled by default and runs in all vSphere clusters. vCLS ensures that if vCenter Server becomes unavailable, cluster services remain available to maintain the resources and health of the workloads that run in the clusters. vCenter Server is still required to run DRS and HA.
But, translated, it means that DRS remains available when vCenter is down.
You may be thinking, “Well, that seems like a good thing.” But . . . allow me to explain . . .
In My Defense: Some Background
As a seasoned VMware Engineer, we “Grey Beards” were told vehemently to plan for vCenter outages in the form of ensuring you have capacity to run, at least for a while, without “luxuries” (emphasis on the quotes) like DRS.
We were told DRS wasn’t “mission critical” if you plan for vCenter failure. Even if you didn’t, VMware has you covered in the form of various other bulwarks.
Which means, the following was beaten into our very noggins:
“Yes. vCenter failure is an emergency and you need to fix it toot sweet. But at least your VMs will stay online until you do. . . . DRS? It can wait.”
Additionally, VMware gives us multiple tools to keep vCenter highly available, like scheduled vCenter config backups, vCenter HA (which is free now, but back in the day it was licensed at $10,000!), snapshots for restores during updates/upgrades, restores from more “traditional” types of external backups, and so on.
Let me put it this way:
In my 14 year career as a VMware Trainer/Engineer, and to this day, I have had DR plans in place that, no matter what, would restore vCenter in less than an hour.
Full stop.
So why the heck is “DRS running while vCenter is unavailable” even a thing? Hmmmm . . .
vCLS: Enter the Crisis
Hopefully, you’re now getting the picture as to why I was exceedingly perplexed about why the heck VMware was marketing vCLS as the greatest freaking thing since the invention of gin. or sliced bread. Or . . . like . . . the wheel, I guess.
My first response to vCLS sent me into an existential crisis. I don’t think VMware should do this to people.
I mean, I get it. It’s marketing, but reading the announcements and the documentation, there’s no couched language. They just come out and say (and I am paraphrasing):
“vCLS keeps DRS running even in the event that vCenter is unavailable.” . . . . FIREWORKS!
They might have well said:
“Hey, old school VMware Engineers everywhere . . . you know how we’ve been telling you for over a decade that it’s totes cool that DRS doesn’t function while vCenter is down temporarily? Well, now we have a feature that makes DRS available while vCenter is down . . . so chew on that, a-holes.”
Hence, it sent me into a psychological spiral that required days of binge drinking1:
- Am I supposed to be planning for capacity differently and be cool with running things tighter since DRS is “more available”?
- Do I not need to plan for the things aforementioned?
- Does this mean we will hear VMware Engineers everywhere, while munching chips, say in an ever so nonchalant way, “Yeah I know it’s Thursday, but we can wait until next Tuesday to get vCenter back online. It’s cool. It’s not really an emergency anymore.”
- Is VMware planning to get rid of vCenter altogether and this is the first salvo?
- Maybe I have had the wrong attitude about DRS for 14 years? Should I have cared all along if DRS isn’t running during the 30-60 minutes it takes for me to restore vCenter availability?
- Have I been lucky in my DR plans to be able to restore vCenter in an hour or less? Does it take longer for some people?
- Maybe this is just “Version 1.0” and they will add more features later?
What made it worse is that it seemed to me, after my usual frantic google searches and blog post reading, literally no one else was asking these questions. Everyone seemed to just shrug their shoulders and say, “It’s cool!”
Turns Out: “they will add more features later” Was Right
So I did the one thing I thought would put my mind at ease:
I asked Duncan Epping about it. Here was the question I asked and his response.
So. As it turns out, DRS availability is just the first feature released, but will have more features in the future.
Which means I have just one more question for you, VMware Marketing Department:
WHY DIDN’T YOU JUST FREAKING SAY THAT IN THE FIRST PLACE?
Questions? Hit me up on twitter @RussianLitGuy or email me at bryansullins@thinkingoutcloud.org. I would love to hear from you.
1 As usual on this blog, future employers, any references to alcoholism or binge-drinking is a joke.
