
This post has everything: Borg Assimilation Cubes, no less than 2 Alec Baldwin movie references, and one Stefon reference. Read on!
. . . Aaaaaaaand I’m back!
Did you miss me? Yes, I took an extended break and I am #SorryNotSorry to my devoted readers.
I have been busy with enjoying the nice weather, trying to lose my “COVID 15” (down 6 pounds!), and my side-project comedy podcast. Thought that would crash and burn, didn’t you?
But now I am ready to get back into blogging!
I am starting out with an easy one here: an opinion post on reverse engineering, but there are more technical posts in the hopper: they mostly deal with Docker, Jenkins, Kubernetes, and VMware, so stay tuned!
Reverse Engineering: A Definition
According to Wikipedia, the definition of Reverse Engineering (for us IT-types) is as follows:
Reverse engineering (also known as backwards engineering or back engineering) is a process or method through the application of which one attempts to understand through deductive reasoning how a device, process, system, or piece of software accomplishes a task with very little (if any) insight into exactly how it does so.
https://en.wikipedia.org/wiki/Reverse_engineering
Although the same skillset of deductive reasoning is used for troubleshooting, reverse engineering is not the same thing. With troubleshooting, you are trying to figure out why things aren’t working, whereas with reverse engineering (arguably a process that is larger in scope) is trying to figure out how everything works, why it works that way, how it’s configured, who configured it and why, and whom to blame if it fails.
OK, that last one is facetious, but you get the point.
Why Reverse Engineering is Important
You may not realize it, but if you are an IT Engineer, you are doing Reverse Engineering more often than you think, like being a fish who doesn’t know what water is.
Anytime you do something new, you’re using the skill.
What is Reverse Engineering? The Borg Assimilation Cube As Onion
Think of reverse engineering like you are trying to figure out how a Borg Cube works (you’re going to have to roll with me on this one; the onion analogy is just too cliché).
You are trying to “peel away” at the layers of the Borg Cube. Start from the outside and work your way in. Follow the circuitry. Follow the chambers and hallways. What’s all the way at the center?
Here’s some information I found:
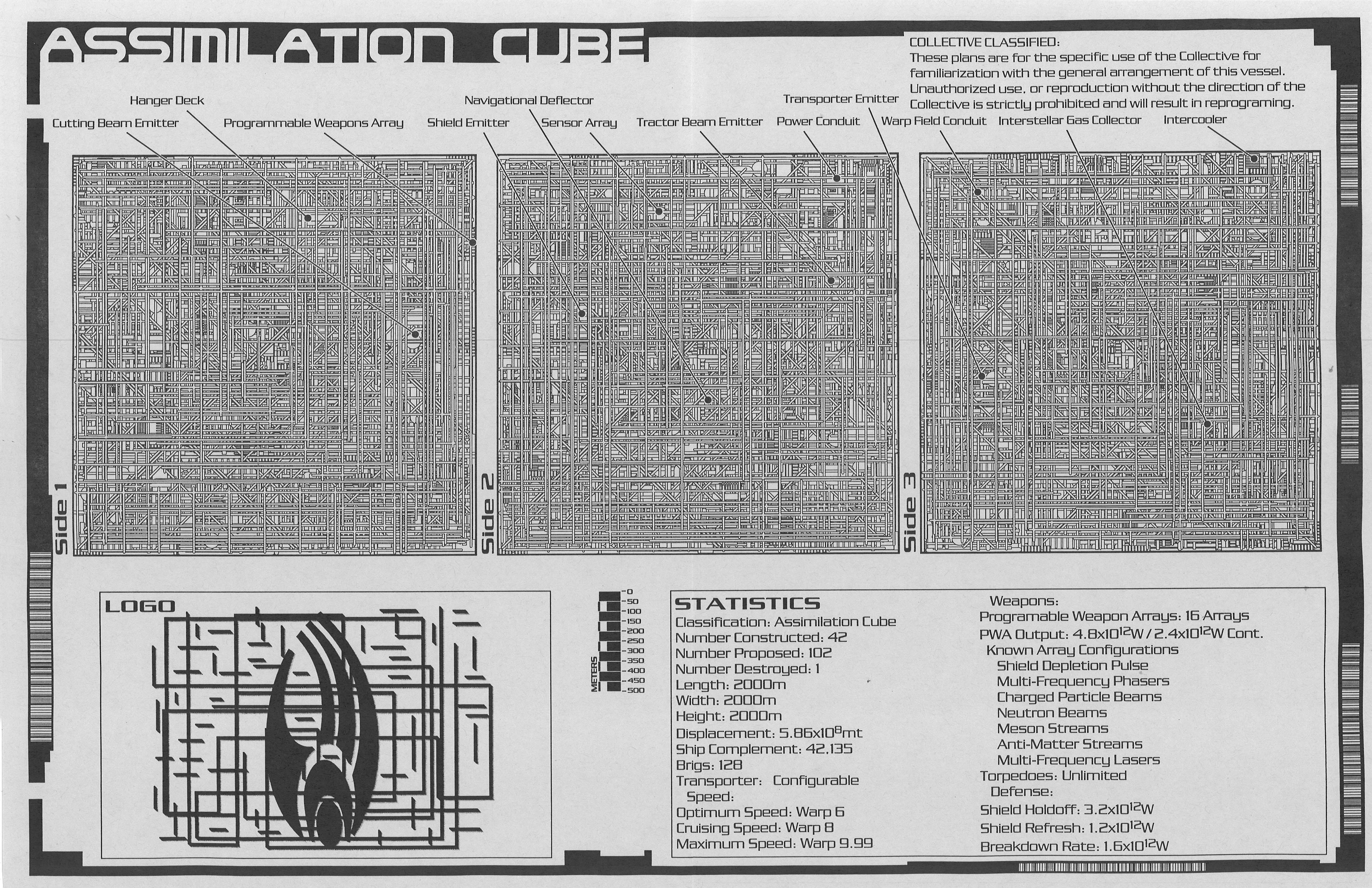
Yes, I am aware I am illuminating the obvious. But are you satisfied with what I found about these mysterious objects? You shouldn’t be.
A good engineer will know about what’s in a Borg cube, and maybe even know the “why” of things.
But a great engineer will go deeper:
- How many Borg Assimilation Cubes are there?
- What is a common number of Borg Drones per cube (and, by the way, what is a Borg Drone anyway)?
- In what parts of the universe do Borg Assimilation Cubes exist?
- Did the Borg always use Assimilation Cubes? What preceded them, if anything?
- How are they built and who builds them?
- Where do they come from and how are they distributed?
- Are there any weaknesses?
- Can a fleet of Borg Cubes destroy the Death Star?
That last question is very important.
In other words, a great engineer will tell you not just, “this is a Borg Cube and its components”. A great engineer will know the entire history of the Borg Cube and why it exists in the first place.
To go back to the Onion analogy, a great Engineer will not ask “What’s at the center of this onion?” A great engineer will ask “Yeah, center of the onion, right . . . whatever. I want to know everything about how and why and who is part of the entire span of history of how all onions and onions like this one came into existence.”
I mean, I just spent the last hour “nerding out” on the timeline of the Borg.
Memories.
That Primer I Promised You
So how do you reverse engineer something?
On that note, now that we know the definition of reverse engineering, what is deductive reasoning anyway? Where did that come from? Why is that even the best tool for it? Are there other tools besides deductive reasoning? What’s the history of reverse engineering and/or deductive reasoning? What are some examples of reverse engineering?
. . . See what I did there? I just . . . you know . . . modeled what I am describing by . . . you know . . . asking a plethora of questions, which is what this post is really about.
But, is it though? Is that really what this post is really about? What if it’s really just about Borg Cubes and Onions? . . .
OK, that’s enough of that.
Let’s make a list of how to do this and apply it as an example.
How to Reverse Engineer anything:
- Get access to the thing. Even if it’s read only or a lab, that will allow you to make some programmatic queries.
- Read the documentation; both internal (if it’s there) and external.
- Start running (harmless) commands. I call this “getting”. In k8s
kubectl get/describeis harmless. It doesn’t change anything. Same with PowerCLIGet-commands. Most everything has the ability to “get”. You can alsogrepsome configuration files, and so on. - Read the documentation again.
- Don’t be afraid to ask others, but respect their time by doing as much as you can on your own. That’s one of the unwritten rules of IT engineering. And, when you do ask, the rule is to have your own theory and confirm: “My theory about __________, based on what I have researched, I think the answer is ________. Am I correct, or am I way off base?”
- Do something simple. While learning Kubernetes, I implemented a non-prod application in a non-prod cluster, just so I could see how it was done. I learned more about Load Balancing and Ingress here and how to configure it because I had to.
- Here’s the one that everyone always forgets (but understandably may not have the time for): Know the history of the thing. Do you remember the Jonesy Reports scene in The Hunt for Red October? This part:
JONESY: "You see, sir, the SAPS software was originally written to look for seismic events. I think when it gets confused, it kind of runs home to Mama."
Think about that: Since he knows everything about what he does to such a deep level, he is able to be smarter than the computer and dig deeper. Without him there is no Hunt for Red October.
For example, I am not saying I have guru status with Linux, but my previous knowledge of it and the history of it in relation to ESXi (Spoiler alert: ESXi is just busybox with a proprietary VMKernel) makes me a much better VMware Engineer. I can’t tell you how many times I have used my Linux knowledge to solve a VMware (ESXi) problem (tcpdump-uw comes to mind).
- Insert Eyeroll Here: Reverse Engineering is an ongoing process, because of course it is, just like freaking everything else in our industry is, AMIRITE? ABRE: Always be Reverse Engineering.
If you are keeping track, that is pop culture reference number 5, if you count the word “Plethora” as a Three Amigos reference.
Kubernetes as an Example
Let’s say you have no experience with Kubernetes. Where do you start? Well, get access to the thing, even if it’s a lab. There are a bunch out there. There’s minikube, but also GCP still has their $300 get-started credit, and that was my first implementation as part of the Kubernetes the Hard Way lesson.
What’s next? Oh yeah, read the documentation. Then, start “getting”:
sh > minikube start
minikube 1.23.0 is available! Download it: https://github.com/kubernetes/minikube/releases/tag/v1.23.0
To disable this notice, run: 'minikube config set WantUpdateNotification false'
✨ Using the docker driver based on existing profile
👍 Starting control plane node minikube in cluster minikube
🚜 Pulling base image ...
🤷 docker "minikube" container is missing, will recreate.
🔥 Creating docker container (CPUs=2, Memory=1985MB) ...
🐳 Preparing Kubernetes v1.21.2 on Docker 20.10.7 ...
🔎 Verifying Kubernetes components...
▪ Using image gcr.io/k8s-minikube/storage-provisioner:v5
🌟 Enabled addons: storage-provisioner, default-storageclass
🏄 Done! kubectl is now configured to use "minikube" cluster and "default" namespace by default
sh > kubectl cluster-info
Kubernetes control plane is running at https://127.0.0.1:61227
CoreDNS is running at https://127.0.0.1:61227/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
sh > kubectl get all --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system pod/coredns-558bd4d5db-ldddj 1/1 Running 1 17d
kube-system pod/etcd-minikube 1/1 Running 1 17d
kube-system pod/kube-apiserver-minikube 1/1 Running 1 17d
kube-system pod/kube-controller-manager-minikube 1/1 Running 1 17d
kube-system pod/kube-proxy-ktvfq 1/1 Running 1 17d
kube-system pod/kube-scheduler-minikube 1/1 Running 1 17d
kube-system pod/storage-provisioner 1/1 Running 2 17d
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 17d
kube-system service/kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 17d
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-system daemonset.apps/kube-proxy 1 1 1 1 1 kubernetes.io/os=linux 17d
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
kube-system deployment.apps/coredns 1/1 1 1 17d
NAMESPACE NAME DESIRED CURRENT READY AGE
kube-system replicaset.apps/coredns-558bd4d5db 1 1 1 17d
Once you read the documentation it will become very clear that there are 4 major components Kubernetes is made of:
- Datacenter concepts. K8s is just a software-defined datacenter, or an “API-defined” datacenter if you want to get specific.
- YAML. It’s how it’s all configured, ultimately.
- REST API calls.
- Web Services.
Yes, I get it, there is much more to it than that, but this is just a start.
Those 4, in and of themselves are all rabbit holes. But if you want to pull everything apart, there you have it. Also, knowing the history, you can study up on where K8s comes from. That has come in handy for me. Spoiler alert: Kubernetes comes from a Google project called . . . . Borg! BOOM! See how I brought that around.
DAMN I AM GOOD.
Next is ask others: bryansullins@thinkingoutcloud.org.
And finally, start doing it. Roll out a load balancer, a Deployment, and Ingress.
Then, rinse repeat. ABRE, right?
Right.
Questions? Hit me up on twitter @RussianLitGuy or email me at bryansullins@thinkingoutcloud.org. I would love to hear from you.

Thank you.
I’m your fan, when I grow up I would be like you. I like how you explain and connect cool things and important ones.
LikeLike
Thanks, man, I appreciate that!
LikeLike